
Your data pipelines are breaking more than you think
The average enterprise collects data from approximately 400 different sources, with larger companies using up to 1,000 resources to meet their BI, AI, and data analytics needs. Each system, whether it is a legacy on-premises database, a cloud data lakehouse, or a growing stack of SaaS APIs, has the potential to fail. And when one of them changes, your pipeline feels the difference.
A Fivetran/Wakefield Research survey of more than 540 data professionals found that engineers spend an average of 44% of their time building and rebuilding pipelines. Across a median team of 12 engineers earning around $98,400 a year, that works out to roughly $520,000 annually in wasted senior capacity—before you factor in the downstream cost of the bad decisions that stale or broken data produces. That is not an engineering failure. That is the expected cost of running deterministic pipelines in a world that refuses to stay deterministic.
Traditional ETL systems were based on the assumption that the structure of incoming data was stable. When an upstream vendor changed an API endpoint, renamed a field, or released a new schema version without notice, the pipeline did not gracefully degrade. It came to a halt. Then someone was paged.
The downstream consequences are rarely contained to the engineering team.
Missed SLAs trigger contractual penalties. Outdated dashboards send executives into quarterly reviews armed with numbers that no longer reflect reality. Machine learning models quietly deteriorate when the data feeding them stops being refreshed—often without anyone noticing until a forecast goes badly wrong. And perhaps most expensively, each incident erodes organizational trust in data, which is the one thing your BI and analytics investments are supposed to build. According to the same Fivetran survey, 71% of respondents said end users are already making business decisions with old or error-prone data—and 66% said their C-suite has no idea. The significance of self-healing data pipelines becomes clear when you map those numbers to their source: not bad luck, but a structural problem with a structural fix.
Self-healing data pipelines—architectures that detect, diagnose, and often resolve failures without human intervention—have matured from an experimental concept into a viable operational approach for businesses willing to implement them properly. The operative phrase is ‘properly.’ Before you start evaluating vendors, there is something important to address: most of what is marketed as ‘self-healing’ is, in fact, not.
What is a self-healing data pipeline in 2026?
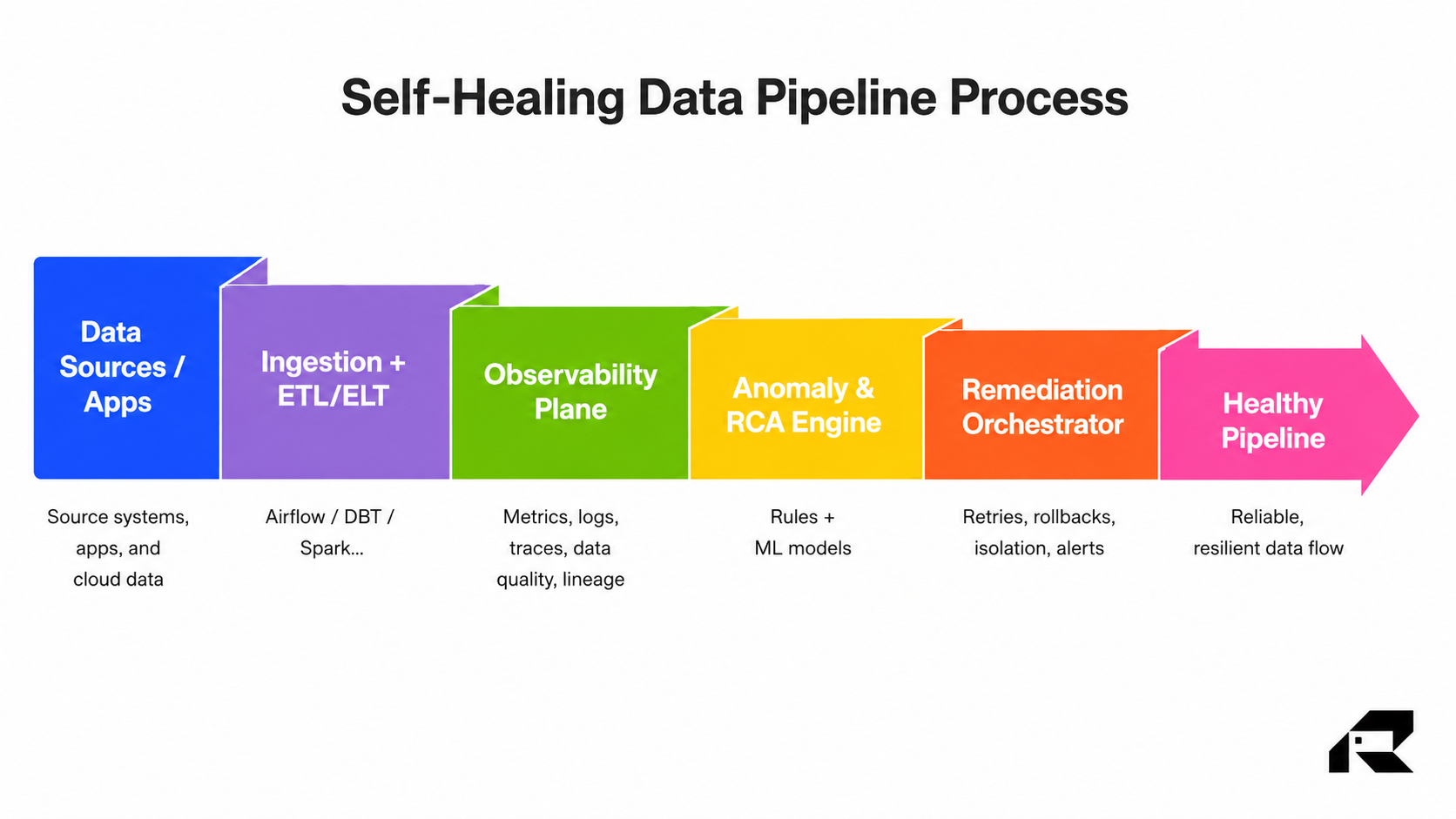
The term refers to a wide range of capabilities, and there is a significant gap between marketing and engineering realities. Senior technology leaders must understand the difference.
Automated retries: Useful, but not transformative
Automatic retry logic with exponential backoff is a foundational data engineering practice. It handles transient failures—a network blip or a momentary server timeout. In practice, it resolves roughly 20% of operational pipeline failures. That is meaningful—but nowhere close to a self-healing system.
To put it plainly, retries assume the problem is temporary and that running the same operation again will succeed. They work when a server is briefly overloaded or a network connection drops for three seconds. They do nothing when the problem is structural—a changed schema, a renamed field, a deprecated API endpoint, or a data source that started sending values in a format the pipeline was never designed to handle. Those failures, which make up the majority of what breaks real-world pipelines, require the system to understand what changed and adapt. Retrying a fundamentally broken operation just generates more errors.
Managed schema drift detection: Outsourced connector maintenance
Platforms like Airbyte handle schema drift by automatically adding new columns or flagging modified data types at the ingestion layer. For their pre-built, supported SaaS connectors, this approach works well—but it is worth understanding what you are actually buying. Think of it less as intelligence and more as delegation: the vendor tracks upstream changes on your behalf for a predefined list of integrations, so your team does not have to. Useful? Yes. Autonomous? Not quite.
The limits become visible quickly when you move outside the supported catalog:
-
Custom internal connectors—any data source your team built or maintains in-house—are outside the platform’s scope entirely. You are responsible for detecting and correcting schema changes yourself.
-
Proprietary or niche enterprise systems (think legacy ERP platforms, industry-specific databases, or bespoke internal APIs) typically have no pre-built connector. Your pipeline is hand-rolled, and so is your maintenance burden.
-
Major API restructurings require understanding the underlying business logic of the change, especially when a vendor overhauls the entire data model instead of just renaming a field. That is something no automated connector can infer. A human engineer has to assess what the new structure means and rewrite the integration accordingly.
In short: managed schema drift detection covers a meaningful slice of the problem for companies running mainstream SaaS stacks. It leaves the harder, more idiosyncratic cases—the ones most common in large enterprises with complex or legacy infrastructure—entirely unaddressed.
What genuine pipeline resilience looks like
A truly self-healing pipeline follows a different principle: rather than assuming stability and reacting when things break, it assumes instability and monitors the health signals of each data flow in near-real time—how many records were received, what proportion of fields were populated, whether the data types matched what the system expected, and whether the statistical distribution of values appeared normal or had shifted. When something appears to be wrong, the pipeline takes action before the problem spreads to downstream systems.
Critically, self-healing pipelines do not halt when bad data appears. Instead of stopping an entire pipeline because one batch contains malformed records, a well-designed system quarantines those records—routing them to what engineers call a Dead-Letter Queue, essentially a holding area for data that needs human review—while clean records continue processing normally. The pipeline keeps running; the anomalies get investigated separately. Modular pipeline design reinforces this principle: by breaking workflows into compartmentalized stages rather than one long chain, a failure in one segment does not cascade into everything downstream. Think of it as the data equivalent of watertight compartments on a ship.
None of this is the result of deploying a single platform and turning on a feature. It is an architectural decision—one that touches how pipelines are structured, how metadata is managed, how monitoring is instrumented, and where AI fits into the picture.
A logistics company we worked with discovered this firsthand: after years of running a bunch of monolithic ETL pipelines that processed loads, inventory, and shipping data in sequence, a single upstream API change from one of the carrier partners would routinely take down the entire daily reporting cycle. Rebuilding pipelines logic (data streaming + pipelines) with modular stages and continuous schema monitoring reduced their incident-driven maintenance from a weekly event to a quarterly one—without replacing their core data platform.
The architecture question: When AI adds value
Continuous monitoring, modular pipeline design, and Dead-Letter Queues solve a large portion of the reliability problem—the structural and operational failures that deterministic engineering can handle. But there is a category of challenge where rigid rules simply run out of road: inconsistent data formats, unstructured inputs, and schema mismatches between sources that share no naming conventions. This is where AI earns its place in the pipeline. The mistake most enterprises make is assuming it belongs everywhere.
The right framework is a hybrid architecture—one that separates tasks by what kind of processing they actually require, rather than applying AI uniformly because it is available.
Standard rule-based processing handles anything that requires precision and full auditability. Payroll calculations. Financial transaction processing. Medical record verification. SLA breach calculations. These are not good candidates for AI involvement. The outputs must be exactly reproducible: given identical inputs, you need identical outputs every time, in a way that can be fully traced and explained to an auditor. Introducing any element of probabilistic reasoning into these workflows is a compliance and trust problem, not a productivity gain.
AI-driven processing earns its place where rigid rules break down. Consider what happens when a pipeline receives sales data from three regional subsidiaries, each with its own formatting of currency, dates, and customer identifiers—and none of which adheres to a consistent naming convention. Writing deterministic rules to cover all variations is fragile and costly to maintain. An AI model can recognize that “Cust_ID,” “customer_number,” and “ClientRef” all refer to the same concept, map them to a unified schema, and flag the cases it is not confident about for human review. The same applies to extracting structured information from unstructured inputs like email threads, PDF contracts, or scanned documents—tasks where the content varies too widely for fixed rules to work reliably.
The practical dividing line is clear: if an incorrect answer results in a financial restatement or a regulatory finding, use standard rule-based processing. If an incorrect answer is detected and reviewed before it moves forward, AI handling is appropriate.
One pattern that illustrates how these two approaches work together is what engineers call “Try-Heal-Retry.” When a standard parsing operation fails on an incoming file—a delimiter mismatch, an encoding shift, or an unexpected multi-line header—instead of terminating the job, the pipeline catches the error and passes a structured description of the problem plus a small sample of the raw data to an AI model. The model diagnoses the issue and returns a suggested fix. The pipeline applies it and retries. For the common failure modes, no human involvement is needed. For the unusual ones, the case gets routed for review. The deterministic pipeline keeps running; the AI layer handles the edge cases it was designed for.
A note on where you run the AI layer

This matters for compliance and cost as much as for performance—and the right answer looks different depending on your industry and data.
A mid-size eCommerce company that updates its product catalog and analyzes customer review sentiment has relatively low data sensitivity and a high tolerance for the occasional processing delay. For them, a cloud-based AI API makes sense: strong capabilities, no infrastructure to manage, and the data involved carries limited regulatory exposure. The per-call costs are predictable at their volume, and the latency is acceptable for a batch process that runs nightly.
A European bank running AI-assisted schema mapping on transaction records is in a fundamentally different position. Sending that data to an external API creates GDPR exposure, potential conflicts with local data residency requirements, and audit trail complications that compliance teams will not sign off on. For them, the AI layer needs to run inside their own infrastructure—hosted within their private cloud or on-premises environment—regardless of what that costs in engineering overhead.
Between those two poles sits the majority of large enterprises: organizations with a mixed portfolio of data types, some sensitive and some not, running pipelines across multiple geographies with varying regulatory requirements. For them, the answer is often a hybrid hosting model—cloud APIs for lower-sensitivity workloads, self-hosted models for anything touching regulated data—which adds architectural complexity but reflects the reality of operating at scale.
There is no universally correct answer, and any vendor insisting otherwise is steering you toward their preferred commercial arrangement. The right choice depends on your data sensitivity, your latency requirements, and your existing cloud posture—and it is worth settling that question before you think about specific tooling.
Anomaly detection: How the AI layer knows something is wrong
Knowing where AI belongs in a self-healing data pipeline is one thing. Understanding how it detects problems in practice is another—and it matters, because the quality of detection determines the quality of everything downstream.
Static threshold alerts—”flag if row count falls below X”—are the most common but also the most brittle. They produce false positives during expected seasonal dips while ignoring gradual drift that never reaches the hard threshold. A retail pipeline that typically processes 500,000 records per day may legitimately process 1.2 million in the week preceding Black Friday. A static alert set to 600,000 triggers every day of the week—not because anything is wrong, but because seasonal volume legitimately exceeds the threshold. After a few days of dismissing identical alerts, the team no longer pays close attention to them. When a genuine failure eventually produces the same pattern, it is also ignored—until something downstream breaks visibly enough to warrant an investigation.
A more reliable approach dynamically tracks volume and batch latency using rolling Z-score calculations. Instead of checking against a fixed number, the pipeline compares each incoming batch to a historical rolling average and standard deviation. When the deviation exceeds a meaningful threshold, it indicates an anomaly—and, more importantly, the baseline is updated on a regular basis, so the system learns what “normal” looks like for that pipeline at that time of year.
Pipelines can use the Kolmogorov-Smirnov test to monitor shifts in how values are distributed—not just how many records arrived, but whether the data itself looks correct—by comparing the distribution of incoming values to a historical baseline. If a field that normally contains transaction amounts ranging from $10 to $500 suddenly starts showing values clustering around $50,000, the test detects it before the records reach a downstream model or report.
These detection signals are fed directly into the self-healing loop: flagged batches are isolated and routed to Dead-Letter Queues for review, clean data continues to flow, and the on-call engineer receives a notification with enough context to investigate—rather than a 3 a.m. page that simply states “pipeline failed.”
Agentic AI & self-healing data pipelines: Promising, with caveats

Detection handles the “something is wrong” problem. The more ambitious frontier is what happens next—can the system not only identify a failure but also diagnose it and initiate a fix without a human in the loop?
The most advanced self-healing data pipeline implementations use autonomous AI agents operating on what is known as the ReAct framework (Reasoning and Acting): the agent evaluates the operational context, forms a hypothesis about what went wrong, selects a diagnostic action, observes the result, and iterates—much like a senior data engineer would work through an incident, but in seconds rather than hours. For the common failure types that data teams deal with repeatedly—think transient API errors, schema drift on known connectors, and volume anomalies within predictable patterns—this loop can resolve incidents end-to-end without involving human specialists.
Whether that translates into meaningful operational improvement in your environment depends on one design decision more than any other: how you scope what the agent is actually allowed to do.
The correct model splits agent access into two clearly separated categories:
-
Read-only diagnostic capabilities—querying Airflow DAG status, pulling Spark job logs, inspecting Delta Lake transaction history, and diffing schema registry changes—are available to the agent autonomously. It can observe, reason, and diagnose without restriction.
-
Write-capable repair actions—schema migrations, job restarts, and target table updates—require human approval before execution. The agent proposes; a person confirms.
It is the correct design for any environment subject to SOX change management, GDPR data handling requirements, or any governance framework that requires immutable audit trails. The agent’s step-by-step reasoning traces serve as audit evidence—every diagnostic decision is logged, inspectable, and attributable. The human approval gate ensures that consequential changes go through a controlled process. Both matter, and they reinforce each other.
Any organization implementing agentic data engineering without maintaining this separation is taking on compliance and operational risk that rarely emerges in vendor case studies but tends to surface rapidly in a regulatory audit.
Self-healing data pipeline platforms: What the main options actually do
The platforms listed below each take a unique approach to the same core problem: detecting pipeline failures early, diagnosing root causes without manual log diving, and initiating fixes—within certain limits—before the engineering team becomes involved. They differ significantly in how they do it, which type of team they suit, and where their limitations lie.
| What it does best | Best fit for | |
|---|---|---|
| Databricks Lakeflow |
Declarative pipelines with automated schema evolution, AutoCDC, and Unity Catalog governance. Genie Code generates and validates pipeline code with human-in-the-loop diffs. |
Organizations already running Databricks; complex enterprise environments needing governance and lineage at scale. |
| Mage Pro AI |
Iteratively rewrites and re-executes failing code blocks across Polars, SQL, and Delta Lake until validation passes. Python-first, notebook-based, fully transparent. |
Data engineering teams that want visibility into every step of the self-healing process and prefer code-first workflows. |
| Qlik / Talend Agentic Routes |
Orchestrates complex record flows, makes semantic transformation choices, and profiles incoming data to propose remediations before manual review. |
Organizations with multi-source integration complexity and mature data stewardship requirements. |
| dbt + dbt Cloud |
Runs data quality tests at the transformation layer on every model run; auto-generated lineage maps downstream impact instantly when a model breaks. dbt Cloud adds job scheduling, CI/CD, and alerts natively. |
SQL-centric teams already using dbt for transformation who want self-healing behavior without introducing a separate observability tool. |
| Dagster + embedded agents |
Open-source orchestrator with built-in asset-based observability; increasingly used as the orchestration backbone for agentic remediation loops. |
Teams building custom self-healing logic who want full control without vendor lock-in. |
| Monte Carlo |
Detects data downtime in real time across freshness, volume, schema, and lineage—automatically tracing root causes without manual triage. |
Teams who need ML-driven anomaly detection without writing rules, especially on Snowflake or BigQuery. |
Real-world adoption bears out the table above.
SEGA rebuilt their streaming platform on Lakeflow Declarative Pipelines specifically to get out of the business of managing fragile, manually maintained jobs—the result was a roughly 4x reduction in pipeline infrastructure costs and sub-5-minute latency from game event to insight, battle-tested during the launch of Football Manager 2026. Felix Baker, Head of Data Services at SEGA Europe, described the outcome plainly: “We literally don’t think about the pipelines anymore. If the studio adds a new event or series of events, Spark Declarative Pipelines just handles it.”
Zillow took a different path to the same platform: after evaluating Databricks’ native data quality features against their existing systems, their engineering team migrated to Lakeflow Declarative Pipelines for scalable, production-grade data quality enforcement across their lakehouse—presenting the approach and results at the 2025 Data + AI Summit.
The harder question is, which platform with self-healing data pipeline capabilities best fits your company’s needs? Stack compatibility, team skill profile, compliance requirements, data sensitivity, and the specific failure modes you are trying to solve all shape the answer in different ways. A platform that works well for a SaaS-heavy eCommerce stack will not necessarily perform the same way for a manufacturing company running a mix of legacy ERP systems and modern cloud infrastructure.
If you are evaluating Databricks specifically, it is worth knowing that ITRex is a registered Databricks consulting and implementation partner. That means hands-on experience with how Lakeflow and Genie Code perform across different enterprise environments—not just what the documentation says, but where the edge cases are and how to architect around them. If another platform makes more sense for your stack, that is the recommendation you will get.
Implementing Self-Healing Pipelines: A Realistic Roadmap

-
Isolate one high-toil pipeline. Pick the pipeline that generates the most maintenance tickets, the most complaints from downstream users, and the most after-hours interventions. That is your proof of concept. A narrow scope gives you fast feedback, a clear before-and-after comparison, and a defensible business case for broader investment. For many organizations, this first stage alone is enough to demonstrate the benefits of self-healing data pipelines to stakeholders who have been skeptical of the investment.
-
Centralize metadata & lineage. Self-healing agents are only as reliable as the context they operate on. Fragmented metadata—pipeline configs in one system, schema registries in another, and lineage documentation in neither—is the fastest path to unreliable automation. Before you build any agent logic, get your observability layer in order. This is also a crucial moment to assess whether your current data platform architecture supports the kind of instrumentation self-healing requires. If you are not sure, a data platform assessment is a practical starting point—it identifies the gaps before you build around them.
-
Build & test agent loops in staging. Agentic behavior should never be developed directly in production. Build in an isolated environment, test against historical failure scenarios, and define in advance exactly which repair actions require human approval. This is also where you establish the audit logging that compliance and governance requirements will eventually demand—and where an experienced data engineering team, whether in-house or external, can significantly shorten the iteration cycle.
-
Define governance before you go live. Document which actions the agent can complete autonomously and which require human approval. Formalize the escalation process for low-confidence decisions. This is not bureaucracy; it is the architectural equivalent of the read-only/write-gated access split we previously discussed, translated into operational policy. By skipping this step, organizations end up with autonomous systems that make significant changes without a traceable approval record.
-
Enable & tune. Once in production, the work is not done—it is just different. Use feedback from successful and failed remediation actions to continuously improve detection sensitivity and healing accuracy. Self-healing data pipelines are an operational capability that matures over time, not a feature you switch on. The organizations that benefit the most from this investment treat the tuning phase as a permanent part of their data engineering practice.
The real-world benefits of self-healing data pipelines
The benefits of self-healing data pipelines are real but worth stating precisely—because the gap between what vendors promise and what well-implemented systems actually deliver is where most disappointments live.
The most direct and measurable impact is on engineering capacity. The Fivetran/Wakefield Research figure cited earlier—44% of data engineering time lost to building and rebuilding pipelines—has genuine room to move once the detection-to-remediation loop is automated for common failure types: schema drift, volume anomalies, and transient API failures. Organizations that implement self-healing architecture at a meaningful scale consistently report that their data teams shift from reactive maintenance to proactive work—better observability design, improved agent behavior, and handling the failure modes that still require human judgment. That is a meaningfully better use of expensive talent than chasing broken DAGs.
The second benefit is reliability compounding over time. A pipeline that fixes its common failures builds a feedback loop: each resolved incident improves detection sensitivity, which improves future resolution rates, which reduces the volume of incidents requiring human escalation. In environments managing data across dozens or hundreds of sources—the average enterprise draws from around 400, according to a Matillion/IDG survey of more than 200 data professionals—that compounding effect is significant.
Two things do not disappear, and any honest assessment needs to say so:
-
Experienced data engineers still matter. Self-healing architecture changes what they spend their time on, not whether you need that talent.
-
Upstream data quality problems must still be addressed. Self-healing data pipelines move clean data faster and more reliably—they do not fix data that is wrong at the source. Bad source data reaches your models and reports with greater efficiency than before. The investment in self-healing architecture belongs alongside investment in upstream data quality, not in place of it.
Implementing self-healing data pipelines: How ITRex can help
Data engineering teams are expensive, and the gap between an architecture whitepaper and a production deployment is where most of the cost lives. Schema evolution in a legacy financial system looks different from schema evolution in a modern cloud warehouse. The compliance requirements of a HIPAA-covered healthcare organization are not the same as those of a manufacturing company running ISO 27001. And the platform that makes sense for a greenfield cloud-native stack is rarely the right answer for an enterprise running a mix of legacy systems and modern infrastructure.
At ITRex, we work with mid-size to large enterprises where this complexity is the norm. We have built data pipelines for organizations managing millions of queries per day across heterogeneous source systems, and we have seen firsthand what happens when self-healing architectures are designed for vendor demos rather than production realities.
On platform selection, our position is straightforward: we do not have a preferred vendor. We are a Databricks consulting and implementation partner, and we have extensive hands-on experience building self-healing pipeline architectures on Snowflake—including its native stack of Streams, Tasks, Time Travel, and Snowpark, which skilled engineers can use to design resilient, automated recovery workflows without reaching for a separate platform. If dbt, Mage Pro AI, or a custom agentic layer fits your architecture better than either, that is what we will recommend and build. The goal is a pipeline ecosystem that runs reliably at your scale, under your compliance requirements, with your team’s ability to maintain it—not a deployment that looks good in a case study and breaks six months later.








