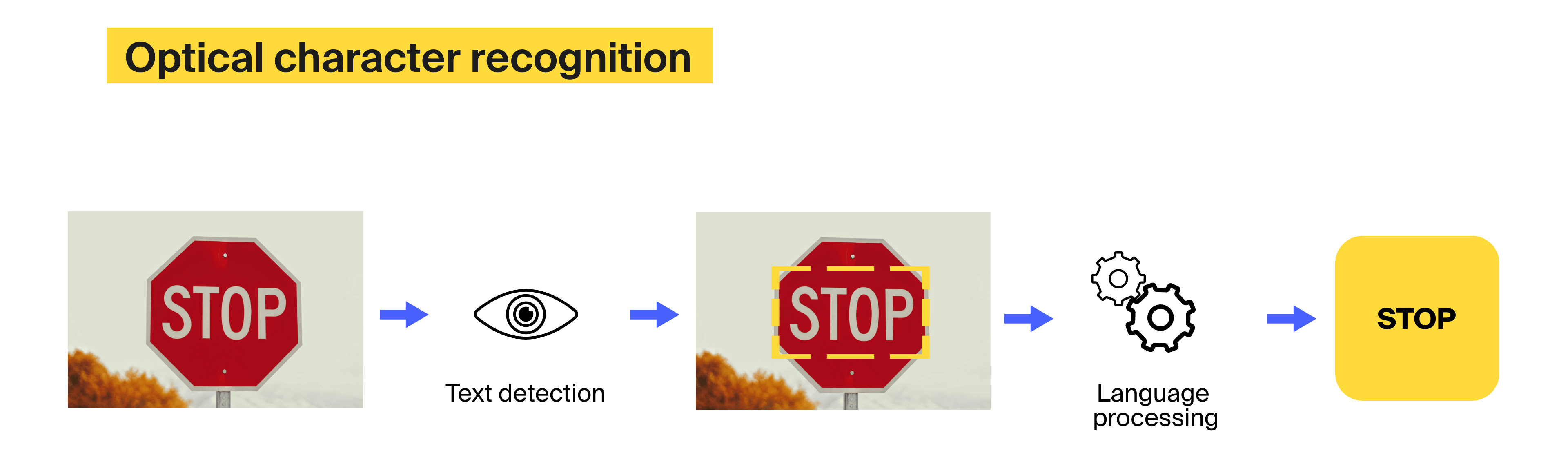
Similar to the banking sector, healthcare organizations accumulate many paper documents, such as X-ray scans, test results, treatment plans, and so on. OCR algorithms help digitize these files to prevent loss of physical documents and reduce efforts wasted on handling paper files manually. Additionally, some OCR solutions that recognize handwritten text can process patient enrollment papers and prescriptions.
Medical claims system
There are software vendors who specialize in OCR-enabled medical claim processing. One such company is
OCR Solutions. It developed a product that can scan, verify, and correctly route medical claims for further handling. This program is trained and configured to work with common formats, such as Dental Claim Forms and CMS-1500, among others.
Fax
Many medical facilities still rely on fax. Optical character recognition solutions can convert incoming material into accessible digitally stored format.
Invoicing
OCR-powered solutions help healthcare organizations digitize invoices and file them correctly. One OCR example comes from San Francisco-based
Nanonets, which offers an OCR-powered solution that specializes in invoice processing. The company claims its software will reduce invoice data entry time from three minutes per invoice to just 30 seconds.