

Hang on a little longer!
Tell us about your challenges, and we’ll come up with a viable solution!






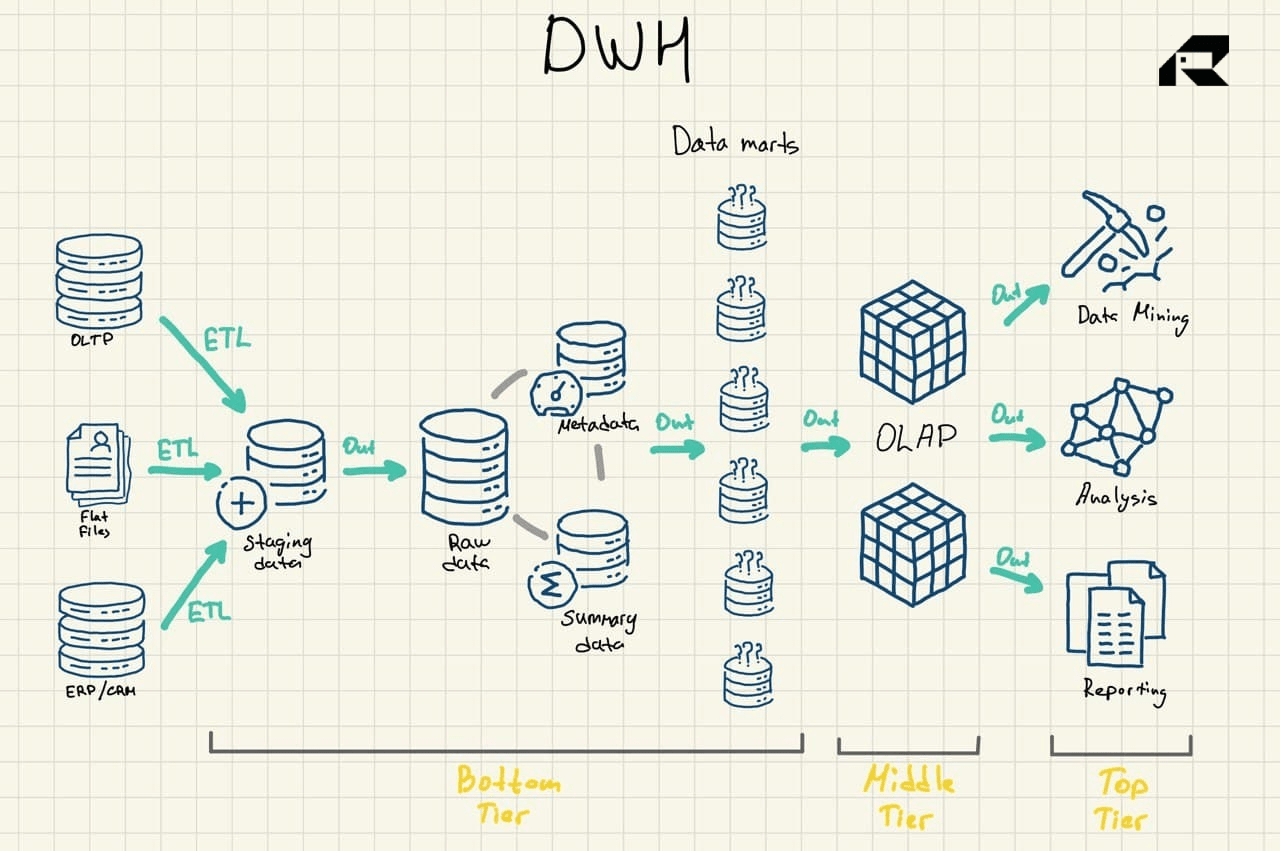
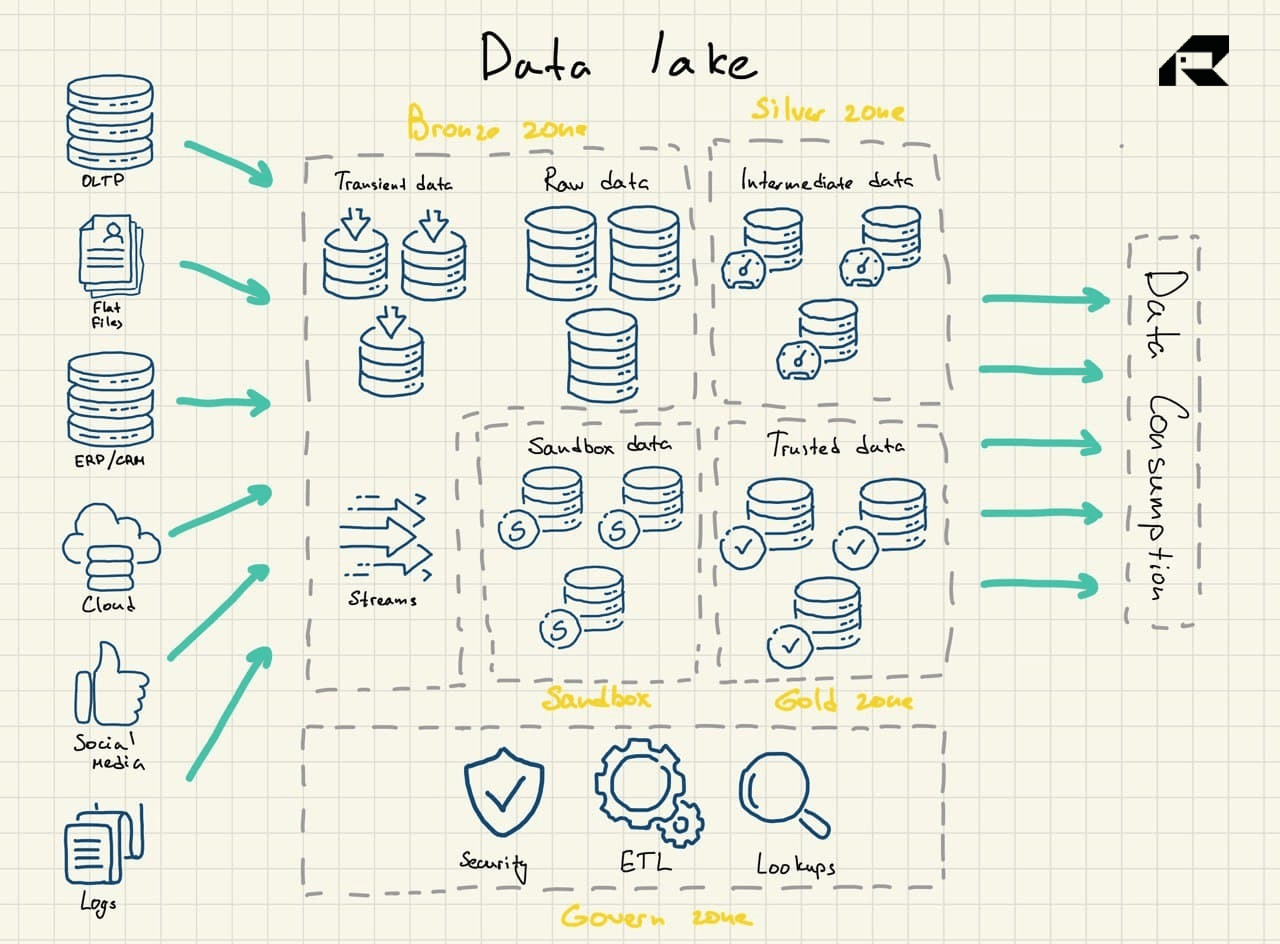
| Characteristics | Data Warehouse | Data Lake |
|---|---|---|
| Types of data | Structured data only | All data, including structured, semi-structured, and unstructured |
| Schema | Pre-defined, fixed schema for data ingest (schema-on-write) | Schema written only at the time of analysis (schema-on-read) |
| Data quality | Highly curated data, reliable | Raw data, low quality, data swamp risk |
| Query | Fast query results upon deployment | Poorly optimized query performance, a lot of data preparation is needed |
| Users | Business professionals | Business analysts, data scientists, data engineers, and data architects |
| Analytics | Reporting, BI, dashboards | Advanced analytics (exploratory analysis, data discovery, streaming analytics, operational analytics, ML, big data) |
| Ease of use | The fixed schema makes data easy to locate, access, and query | Time and effort is required to organize and prepare data for use. Extensive coding is involved |
| Scalability | Scaling might be difficult because of tightly coupled storage and compute | Scaling is easy and cost-effective because of separation of storage and compute |
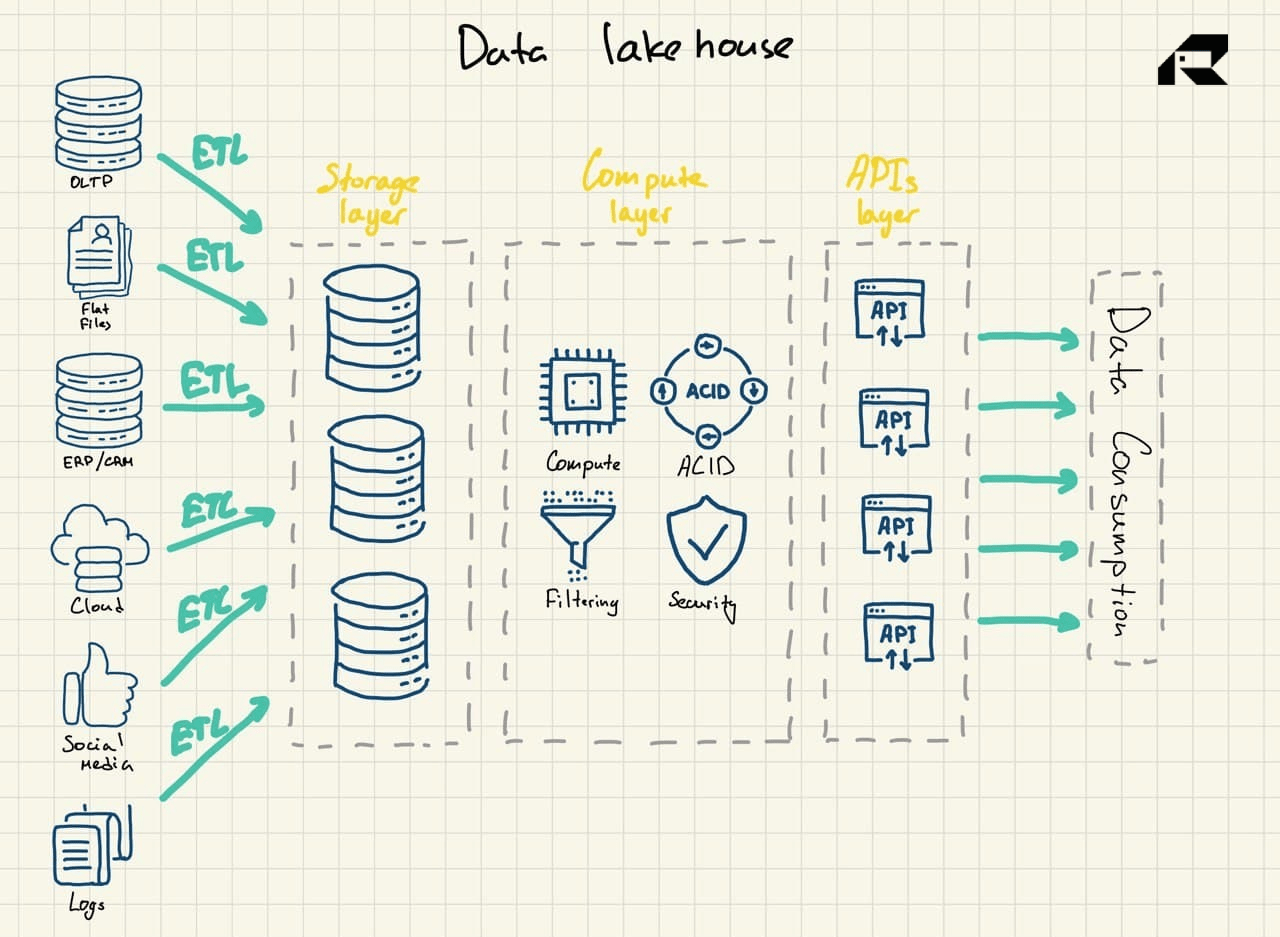
| Characteristic | Data Lake | Data Lakehouse |
|---|---|---|
| Types of data | All data, including structured, semi-structured, and unstructured | All data, including structured, semi-structured, and unstructured |
| Schema | No pre-defined schema | Schema enforcement |
| Data quality | Raw data, low quality, data swamp risk | Raw and curated data, high quality enabled by in-built data governance |
| Query | Poorly optimized query performance | Highly optimized query performance |
| Users | Business analysts, data scientists, data engineers, and data architects | Business professionals and data teams |
| Ease of use | Difficult | Simple, with data lakehouses providing interfaces similar to traditional data warehouses together with in-built AI support |
| Analytics | Advanced analytics | Suitable for all types of analytics workflows, both advanced analytics and BI |
| Scaling | Easy | Easy |
Tell us about your challenges, and we’ll come up with a viable solution!
