Struggling to harness data sprawl, CIOs across industries are facing tough challenges. One of them is where to store all of their enterprise’s data to deliver
robust data analytics.
There have traditionally been two storage solutions for data:
data warehouses and data lakes.
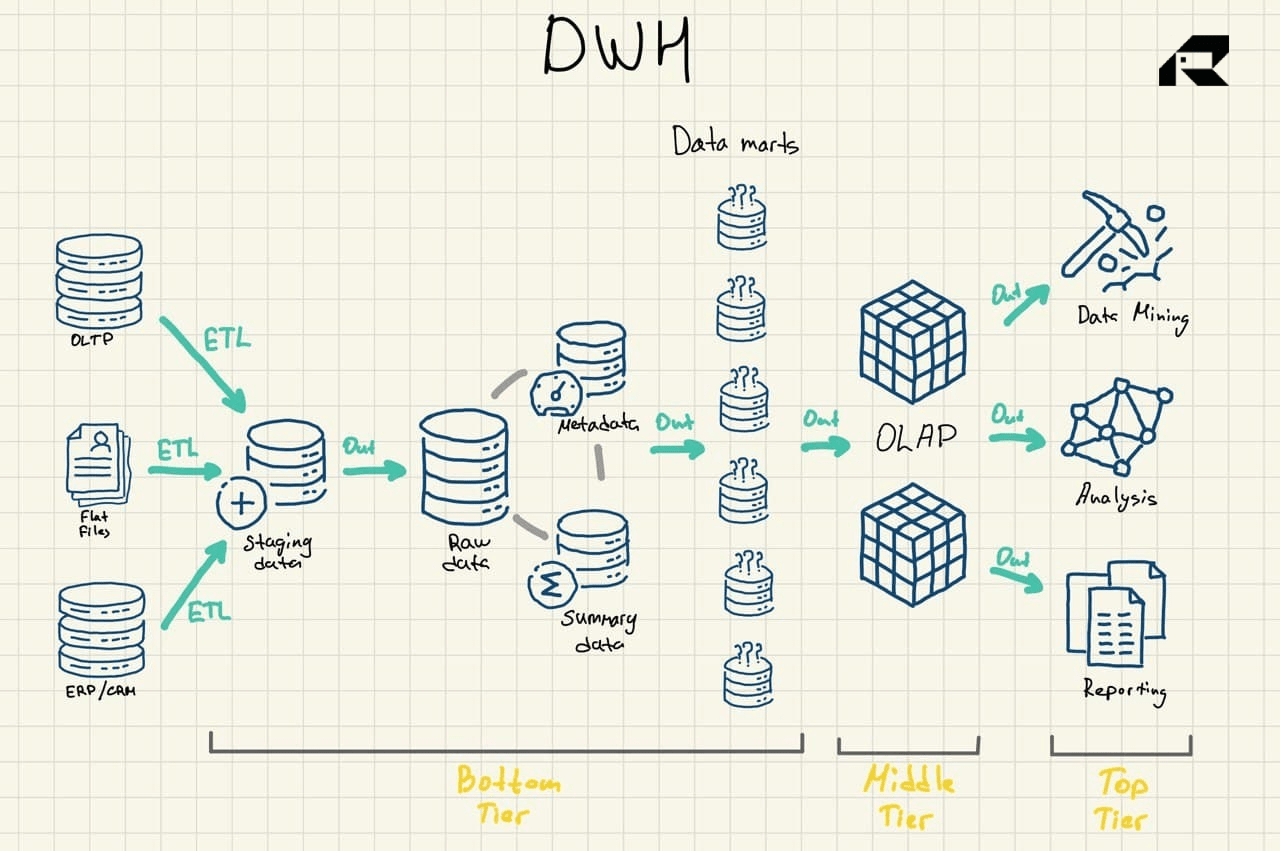
Data warehouses mainly store transformed, structured data from operational and transactional systems, and are used for fast complex queries across this historical data.
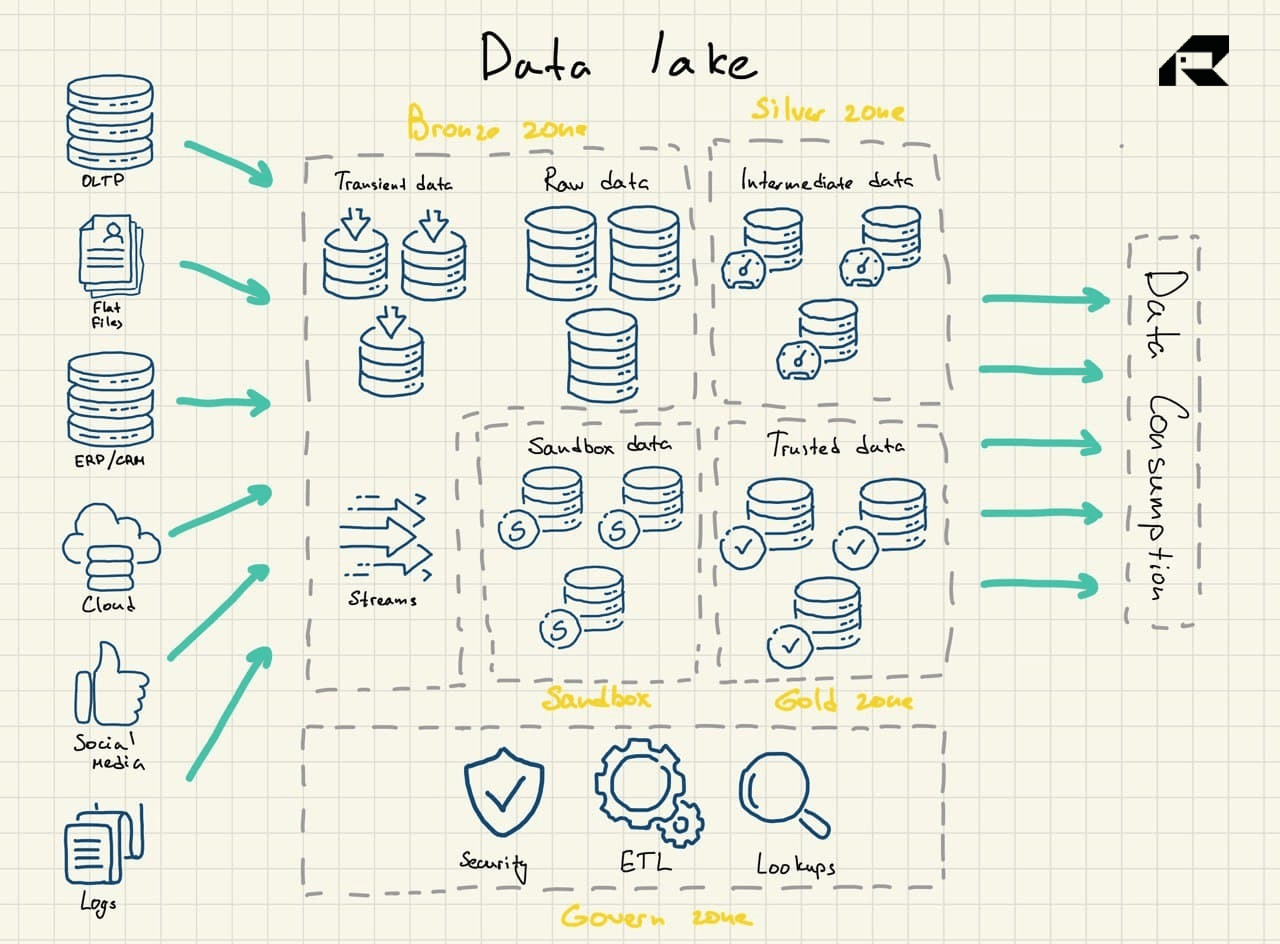
Data lakes act as a dump, storing all kinds of data, including
semi-structured and unstructured data. They empower advanced analytics like streaming analytics for live data processing or machine learning.
Historically, data warehouses were expensive to roll out because you needed to pay for both the storage space and computing resources, apart from skills to maintain them. As the cost of storage has declined, data warehouses have become cheaper. Some believe data lakes (traditionally a more cost-efficient alternative) are now dead. Some argue data lakes are still trendy. Meanwhile, others are talking about
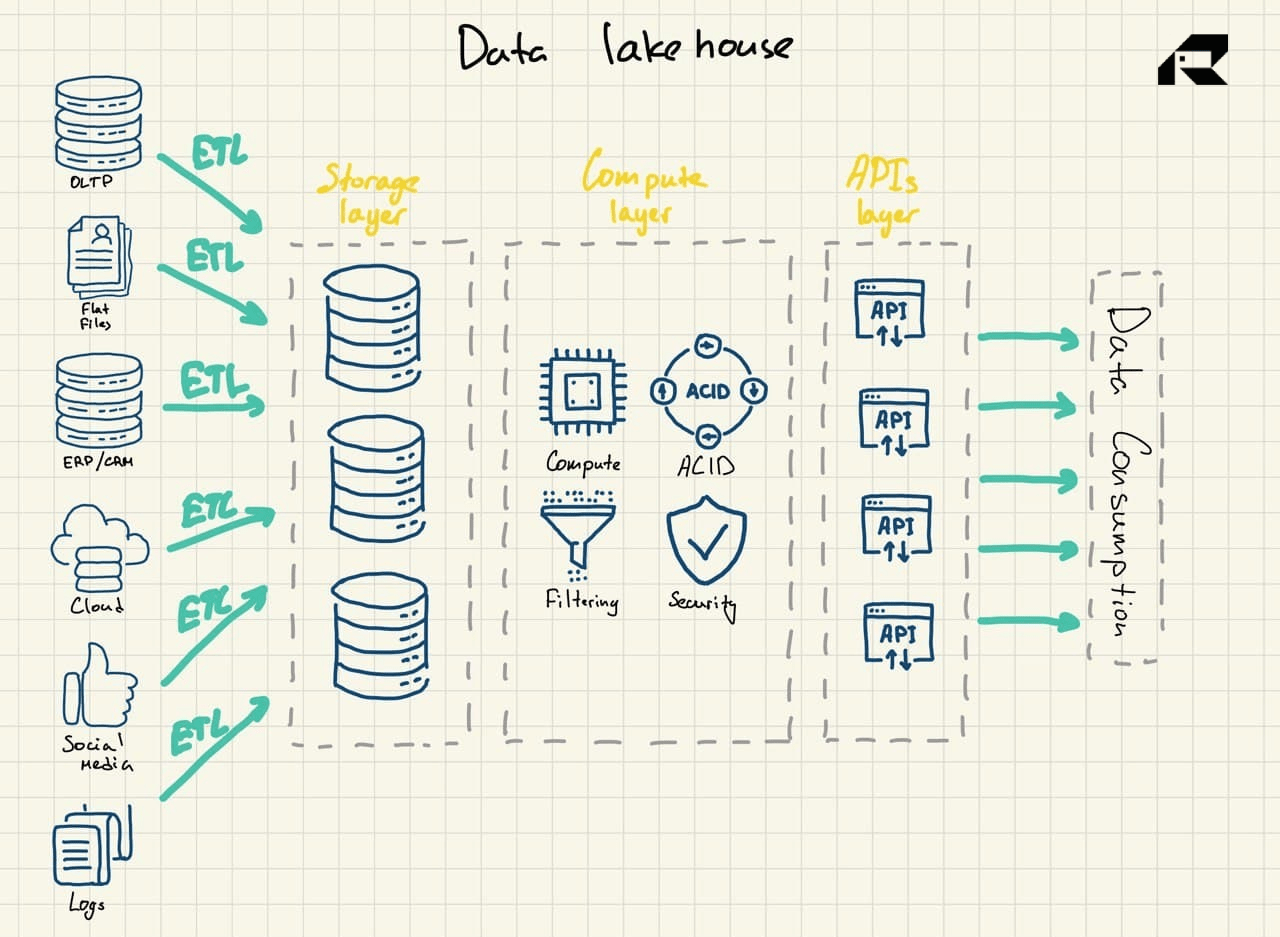
a new, hybrid data storage solution - data lakehouses.
What’s the deal with each of them? Let’s take a close look.
This blog explores key differences between data warehouses, data lakes, and data lakehouses, popular tech stacks, and use cases. It also provides tips for choosing the right solution for your company, though this one is tricky.