
What is synthetic data, and how does it differ from mock data?

Before we delve into the specifics of synthetic data generation using generative AI, we need to explain the synthetic data meaning and compare it to mock data. A lot of people just get the two confused, though these are two distinct approaches, each serving a different purpose and generated through different methods.
Synthetic data refers to data created by deep generative algorithms trained on real-world data samples. To generate synthetic data, algorithms first learn patterns, distributions, correlations, and statistical characteristics of the sample data and then replicate genuine data by reconstructing these properties. As we mentioned above, real-world data may be scarce or inaccessible, which is particularly true for sensitive domains like healthcare and finance where privacy concerns are paramount. Synthetic data generation eliminates privacy issues and the need for access to sensitive or proprietary information while producing massive amounts of safe and highly functional artificial data for training machine learning models.
Mock data, in turn, is typically created manually or using tools that generate random or semi-random data based on predefined rules for testing and development purposes. It is used to simulate various scenarios, validate functionality, and evaluate the usability of applications without depending on actual production data. It may resemble real data in structure and format but lacks the nuanced patterns and variability found in actual datasets.
Overall, mock data is prepared manually or semi-automatically to mimic real data for testing and validation, whereas synthetic data is generated algorithmically to duplicate real data patterns for training AI models and running simulations.
Key use cases for Gen AI-produced synthetic data

-
Enhancing training datasets and balancing classes for ML model training
In some cases, the dataset size can be excessively small, which could affect the ML model’s accuracy, or the data in a dataset can be imbalanced, meaning that not all classes have an equal number of samples, with one class being substantially underrepresented. Upsampling minority groups with synthetic data helps balance the class distribution by increasing the number of instances in the underrepresented class, thereby improving model performance. Upsamling implies generating synthetic data points that resemble the original data and adding them to the dataset.
-
Replacing real-world training data in order to stay compliant with industry- and region-specific regulations
Synthetic data generation using generative AI is widely applied to design and verify ML algorithms without compromising sensitive tabular data in industries including healthcare, banking, and the legal sector. Synthetic training data mitigates privacy concerns associated with using real-world data as it doesn’t correspond to real individuals or entities. This allows organizations to stay compliant with industry- and region-specific regulations, such as, for example, IT healthcare standards and regulations, without sacrificing data utility. Synthetic patient data, synthetic financial data, and synthetic transaction data are privacy-driven synthetic data examples. Think, for example, about a scenario in which medical research generates synthetic data from a live dataset; all names, addresses, and other personally identifiable patient information are fictitious, but the synthetic data retains the same proportion of biological characteristics and genetic markers as the original dataset.
-
Creating realistic test scenario
Generative AI synthetic data can simulate real-world environments, such as weather conditions, traffic patterns, or market fluctuations, for testing autonomous systems, robotics, and predictive models without real-world consequences. This is especially beneficial in applications where testing in harsh environments is necessary yet impracticable or risky, like autonomous cars, aircraft, and healthcare. Besides, synthetic data allows for the creation of edge cases and uncommon scenarios that may not exist in real-world data, which is essential for validating the resilience and robustness of AI systems. This covers extreme circumstances, outliers, and anomalies.
-
Enhancing cybersecurity
Synthetic data generation using generative AI can bring significant value in terms of cybersecurity. The quality and diversity of the training data are critical components for AI-powered security solutions like malware classifiers and intrusion detection. Generative AI-produced synthetic data can cover a wide range of cyber attack scenarios, including phishing attempts, ransomware attacks, and network intrusions. This variety in training data makes sure AI systems are capable of identifying security vulnerabilities and thwarting cyber threats, including ones that they may not have faced previously.
How generative AI synthetic data helps create better, more efficient models
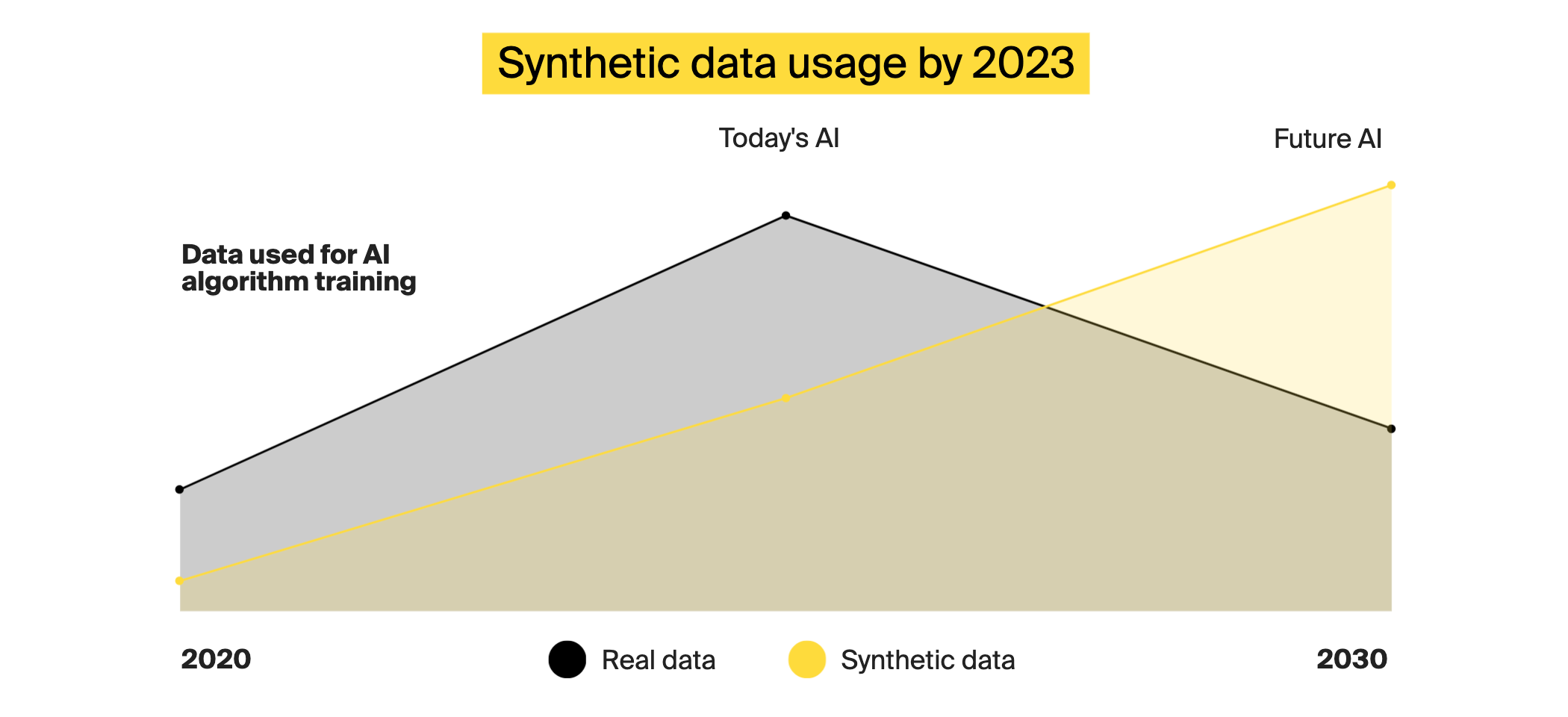
Gartner estimates that by 2030, synthetic data will entirely replace real data in AI models. The benefits of synthetic data generation using generative AI extend far beyond preserving data privacy. It underpins advancements in AI, experimentation, and the development of robust and reliable machine learning solutions. Some of the most critical advantages that significantly impact various domains and applications are:
-
Breaking the dilemma of privacy and utility
Access to data is essential for creating highly efficient AI models. However, data use is limited by privacy, safety, copyright, or other regulations. AI-generated synthetic data provides an answer to this problem by overcoming the privacy-utility trade-off. Companies do not need to use traditional anonymizing techniques, such as data masking, and sacrifice data utility for data confidentiality any longer, as synthetic data generation allows for preserving privacy while also giving access to as much useful data as needed.
-
Enhancing data flexibility
Synthetic data is much more flexible than production data. It can be produced and shared on demand. Besides, you can alter the data to fit certain characteristics, downsize big datasets, or create richer versions of the original data. This degree of customization allows data scientists to produce datasets that cover a variety of scenarios and edge cases not easily accessible in real-world data. For example, synthetic data can be used to mitigate biases embedded in real-world data.
-
Reducing costs
Traditional methods of collecting data are costly, time-consuming, and resource-intensive. Companies can significantly lower the total cost of ownership of their AI projects by building a dataset using synthetic data. It reduces the overhead related to collecting, storing, formatting, and labeling data—especially for extensive machine learning initiatives.
-
Increasing efficiency
One of the most apparent benefits of generative AI synthetic data is its ability to expedite business procedures and reduce the burden of red tape. The process of creating precise workflows is frequently hampered by data collection and training. Synthetic data generation drastically shortens the time to data and allows for faster model development and deployment timelines. You can obtain labeled and organized data on demand without having to convert raw data from scratch.
How does the process of synthetic data generation using generative AI unfold?
The process of synthetic data generation using generative AI involves several key steps and techniques. This is a general rundown of how this process unfolds:
-
The collection of sample data
Synthetic data is sample-based data. So the first step is to collect real-world data samples that can serve as a guide for creating synthetic data.
-
Model selection and training
Choose an appropriate generative model based on the type of data to be generated. The most popular deep machine learning generative models, such as Variational Auto-Encoders (VAEs), Generative Adversarial Networks (GANs), diffusion models, and transformer-based models like large language models (LLMs), require less real-world data to deliver plausible results. Here’s how they differ in the context of synthetic data generation:
-
VAEs work best for probabilistic modeling and reconstruction tasks, such as anomaly detection and privacy-preserving synthetic data generation
-
GANs are best suited for generating high-quality images, videos, and media with precise details and realistic characteristics, as well as for style transfer and domain adaptation
-
Diffusion models are currently the best models for generating high-quality images and videos; an example is generating synthetic image datasets for computer vision tasks like traffic vehicle detection
-
LLMs are primarily used for text generation tasks, including natural language responses, creative writing, and content creation
-
-
Actual synthetic data generation
After being trained, the generative model can create synthetic data by sampling from the learned distribution. For instance, a language model like GPT might produce text token by token, or a GAN could produce graphics pixel by pixel. It is possible to generate data with particular traits or characteristics under control using methods like latent space modification (for GANs and VAEs). This allows the synthetic data to be modified and tailored to the required parameters.
-
Quality assessment
Assess the quality of the artificially generated data by contrasting statistical measures (such as mean, variance, and covariance) with those of the original data. Use data processing tools like statistical tests and visualization techniques to evaluate the authenticity and realism of the synthetic data.
-
Iterative improvement and deployment
Integrate synthetic data into applications, workflows, or systems for training machine learning models, testing algorithms, or conducting simulations. Improve the quality and applicability of synthetic data over time by iteratively updating and refining the generating models in response to new data and changing specifications.
This is just a general overview of the essential phases companies need to go through on their way to synthetic data. If you need assistance with synthetic data generation using generative AI, ITRex offers a full spectrum of generative AI development services, including synthetic data creation for model training. To help you synthesize data and create an efficient AI model, we will:
-
assess your needs,
-
recommend suitable Gen AI models,
-
help collect sample data and prepare it for model training,
-
train and optimize the models,
-
generate and pre-process the synthetic data,
-
integrate the synthetic data into existing pipelines,
-
and provide comprehensive deployment support.
To sum up
Synthetic data generation using generative AI represents a revolutionary approach to producing data that closely resembles real-world distributions and increases the possibilities for creating more efficient and accurate ML models. It enhances dataset diversity by producing additional samples that supplement the existing datasets while also addressing challenges in data privacy. Generative AI can simulate complex scenarios, edge cases, and rare events that may be challenging or costly to observe in real-world data, which supports innovation and scenario testing.
By utilizing advanced AI and ML techniques, enterprises can unleash the potential of synthetic data generation to spur innovation and achieve more robust and scalable AI solutions. This is where we can help. With extensive expertise in data management, analytics, strategy implementation, and all AI domains, from classic ML to deep learning and generative AI, ITRex will help you develop specific use cases and scenarios where synthetic data can add value.









