
Understanding data masking
So, what is data masking?
Data masking is defined as building a realistic and structurally similar, but nonetheless fake version of the organizational data. It alters the original data values using manipulation techniques while maintaining the same format, and delivers a new version that can’t be reverse-engineered or tracked back to the authentic values.
Here is an example of masked data:

Do you need to apply data masking algorithms to all the data stored within your company? Most likely not. Here are the data types that you definitely need to protect:
-
Protected Health Information (PHI) includes medical records, lab tests, medical insurance information, and even demographics.
-
Payment card information is related to credit and debit card information and transactions data under the Payment Card Industry Data Security Standard (PCI DSS).
-
Personally identifiable information (PII), such as passport and social security numbers. Basically, any piece of information that can be used to identify a person.
-
Intellectual property (IP) includes inventions, such as designs, or anything that has value to the organization and can be stolen.
Why do you need data masking?
Data masking protects sensitive information utilized for non-productive purposes. So, as long as you use any of the sensitive data types presented in the previous section in training, testing, sales demos, or any other types of non-production activities, you need to apply data masking techniques. This makes sense as non-production environments are normally less protected and introduce more security vulnerabilities.
Moreover, if there is a need to share your data with third-party vendors and technology partners, you can grant access to masked data instead of forcing the other party to comply with your extensive security measures to access the original database. Statistics show that 19% of data breaches take place due to compromises on the business partner’s side.
Additionally, data masking can provide the following advantages:
-
Renders organizational data useless to cybercriminals in case they are able to access it
-
Reduces risks posed by sharing data with authorized users and outsourcing projects
-
Helps comply with data privacy and security-related regulations, such as the General Data Protection Regulation (GDPR), the Health Insurance Portability and Accountability Act (HIPAA), and any other regulations applicable within your field
-
Protects data in the case of deletion, as the conventional file deletion methods still leave a trace of the old data values
-
Safeguards your data in the case of unauthorized data transfer
Data masking types
There are five main types of data masking that aim to cover different organizational needs.
1. Static data masking
Implies creating a backup of the original data and keeping it safe in a separate environment for production use cases. Then it disguises the copy by including fake but realistic values, and makes it available for non-production purposes (e.g., testing, research), as well as sharing with contractors.

2. Dynamic data masking
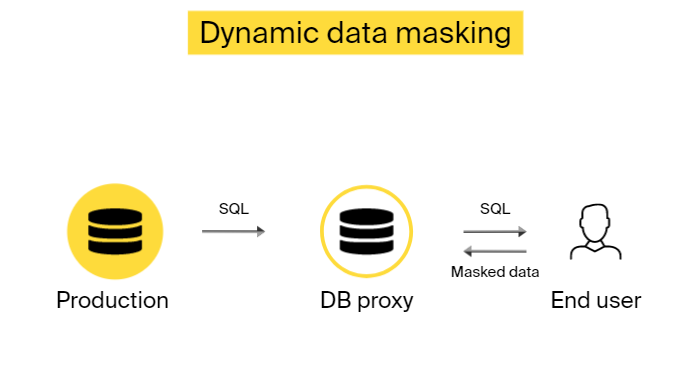
Aims to modify an excerpt of the original data at runtime when receiving a query to the database. So, a user who is not authorized to view sensitive information queries the production database, and the response is masked on the fly without changing the original values. You can implement it via database proxy, as presented below. This data masking type is normally used in read-only settings to prevent overriding production data.
3. On-the-fly data masking
This data masking type disguises data when transferring it from one environment to another, such as from production to testing. It is popular with organizations that continuously deploy software and perform large data integrations.
4. Deterministic data masking
Replaces column data with the same fixed value. For instance, if you want to replace “Olivia” with “Emma”, you have to do it in all the associated tables, not only in the table you are currently masking.
5. Statistical data obfuscation
This is used to reveal information about patterns and trends in a dataset without sharing any details on actual people represented there.
7 main data masking techniques
Below you can find seven of the most popular data masking techniques. You can combine them to cover the various needs of your business.
-
Shuffling. You can shuffle and reassign data values within the same table. For example, if you shuffle the employee name column, you will get the real personal details of one employee matched to another.
-
Scrambling. Rearranges characters and integers of a data field in a random order. If an employee’s original ID is 97489376, after applying shuffling, you will receive something like 37798649. This is restricted to specific data types.
-
Nulling out. This is a simple masking strategy where a data field is assigned a null value. This method has limited usage as it tends to fail the application’s logic.
-
Substitution. Original data is substituted by fake, but realistic values. Meaning that the new value still needs to satisfy all domain constraints. For instance, you substitute someone’s credit card number with another number that conforms to the rules enforced by the issuing bank.
-
Number variance. This is mostly applicable to financial information. One example is masking original salaries by applying +/-20% variance.
-
Date aging. This method increases or decreases a date by a specific range, maintaining that the resulting date satisfies the application’s constraints. For instance, you can age all contracts by 50 days.
-
Averaging. Involves replacing all the original data values by an average. For instance, you can replace every individual salary field by an average of salary values in this table.
How to implement data masking the right way?
Here is your 5-step data masking implementation plan.
Step 1: Determine the scope of your project
Before you start, you will need to identify which aspects you will cover. Here is a list of typical questions that your data team can study before proceeding with the masking initiatives:
-
Which data are we looking to mask?
-
Where does it reside?
-
Who is authorized to access it?
-
What is the access level of each user from the above? Who can only view and who can alter and delete values?
-
Which applications are utilizing this sensitive data?
-
What impact will data masking have on different users?
-
What level of masking is required, and how often will we need to repeat the process?
-
Are we looking to apply data masking across the whole organization or limit it to a specific product?
Step 2: Define the stack of data masking techniques
During this step, you need to identify which technique or a combination of data masking tools are the best fit for that task at hand.
First of all, you need to identify which data types you need to mask, for instance, names, dates, financial data, etc., as different types require dedicated data masking algorithms. Based on that, you and your vendor can choose which open source library(s) can be reused to produce the best-suited data masking solution. We advise turning to a software vendor, as they will help you customize the solution and integrate it painlessly into your workflows across the whole company without interrupting any business processes. Also, it’s possible to build something from zero to cover the company’s unique needs.
There are ready-made data masking tools that you can purchase and deploy yourself, such as Oracle Data Masking, IRI FieldShield, DATPROF, and many more. You can opt for this strategy if you manage all your data by yourself, you understand how different data flows work, and you have an IT department who can help integrate this new data masking solution into the existing processes without hindering productivity.
Step 3: Secure your selected data masking algorithms
The security of your sensitive data largely depends on the security of the selected fake data-generating algorithms. Therefore, only authorized personnel can know which data masking algorithms are deployed, as these people can reverse engineer the masked data to the original dataset with this knowledge. It’s a good practice to apply separation of duties. For instance, the security department selects the best suited algorithms and tools, while data owners maintain the settings applied in masking their data.
Step 4: Preserve referential integrity
Referential integrity means that each data type within your organization is masked in the same way. This can be a challenge if your organization is rather large and has several business functions and product lines. In this case your company is likely to use different data masking algorithms for various tasks.
To overcome this issue, identify all the tables that contain referential constraints and determine in which order you will mask the data as parent tables should be masked before the corresponding child tables. After completing the masking process, do not forget to check whether referential integrity was maintained.
Step 5: Make the masking process repeatable
Any adjustment to a particular project, or just general changes within your organization, can result in modifying the sensitive data and creating new data sources, posing the need to repeat the masking process.
There are instances where data masking can be a one-time effort, such as in the case of preparing a specialized training dataset that will be used for a few months for a small project. But if you want a solution that will serve you for a prolonged time, your data can become obsolete at one point. So, invest time and effort in formalizing the masking process to make it fast, repeatable, and as automated as possible.
Develop a set of masking rules, such as which data has to be masked. Identify any exceptions or special cases that you can foresee at this point. Acquire/build scripts and automated tools to apply these masking rules in a consistent manner.
Your checklist for selecting a data masking solution
Whether you work with a software vendor of your choice or opt for a ready-made solution, the final product needs to follow these data masking best practices:
-
Be non-reversible, making it impossible to reverse engineer the fake data to its authentic values
-
Protect the integrity of the original database and doesn’t render it useless by making permanent changes by mistake
-
Mask non-sensitive data if this is necessary to protect sensitive information
-
Provide an opportunity for automation, as the data will change at some point and you don’t want to start from zero every time
-
Generate realistic data that maintains the structure and the distribution of the original data, and satisfies business constraints
-
Be scalable to accommodate any additional data sources that you want to incorporate into your business
-
Compliant with all the applicable regulations, such as HIPAA and GDPR, and your internal policies
-
Integrate well into the existing systems and workflows
Data masking challenges
Here is a list of challenges that you might face during implementation.
-
Format preservation. The masking solution has to understand the data and be able to preserve its original format.
-
Gender preservation. The selected data masking methodology needs to be aware of the gender when masking people’s names. Otherwise, the gender distribution within the dataset will be altered.
-
Semantic integrity. The generated fake values need to follow the business rules restricting different data types. For instance, salaries have to fall within a specific range, and social security numbers have to follow a predetermined format. This is also true for maintaining the geographical distribution of the data.
-
Data uniqueness. If the original data has to be unique, like employee ID number, the data masking technique needs to supply a unique value.
-
Balancing security and usability. If the data is too heavily masked, it can become useless. On the other hand, if it’s not protected enough, users can gain unauthorized access.
-
Integrating the data into the existing workflows might be highly inconvenient to employees in the very beginning, as people are used to work in a certain way, which is currently being disrupted.
A data masking example from the ITRex portfolio
An international healthcare organization was looking to obscure sensitive personally identifiable information (PII) presented in multiple formats and residing in both production and non-production environments. They wanted to build an ML-powered data masking software that can discover and obfuscate PII while complying with the company’s internal policies, GDPR, and other data privacy regulations.
Our team immediately noticed the following challenges:
-
The client had enormous volumes of data, over 10,000 data sources, and many corresponding data flows
-
There was no clear data masking strategy that would cover all the different departments
Due to this large variety, our team wanted to come up with a set of policies and processes that would guide different dataset owners on how to mask their data and would serve as the basis for our solution. For instance, someone could come with the list of data points that they want to obfuscate whether once or continuously, and the solution, guided by these principles, would study the data and select appropriate obfuscation techniques and apply them.
We approached this project by surveying the landscape through the following questions:
-
Which data management solutions are you using? The client was already using Informatica, so we went with that. Informatica’s data masking solution offers out of the box features, which satisfied some of the client’s needs but this wasn’t enough to cover all the requirements.
-
Which data types are you willing to mask? Due to the large number of data sources, it was impossible to address everything at once. So, we asked the client to prioritize and identify what was mission critical.
-
Do you want to do it one time, or make it a repeatable process?
After answering these questions, we suggested to provide data masking as a service mainly because the client has too many data sources to begin with and it might have taken years to cover them all.
In the end, we delivered data masking services with the help of a custom ML-driven tool that can semi-automatically perform data masking in four steps:
-
Identify data types. Data owners put their data sources into the analysis tool that studies the columns’ data and reveals the data types it could identify in these columns, such as addresses, phone numbers, etc. A human expert verifies its output, allowing it to learn from mistakes.
-
Suggest masking approaches for each column and apply them after human approval
-
Deploy the results. After the masked data is generated, it needs to be deployed. We provided multiple options for data storage. This includes, but not limited to using a temporary database that remains live for several days, assigning a permanent location for masked environments, generating comma-separated values (CSVs) files, and more.
-
Examine and give a badge of approval to a set of data or a set of environments as a proof that they are properly masked and compliant
This data masking solution helped the client comply with GDPR, dramatically reduced the time needed to form non-production environments, and lowered the costs of transferring data from production to sandbox.
How to maintain masked data after implementation?
Your efforts do not stop when the confidential data is masked. You still need to maintain it over time. Here are the steps that will help you in this initiative:
-
Establish policies and procedures that govern the masked data. This includes determining who is authorized to access this data and under which circumstances, and which purposes this data serves (e.g., testing, reporting, research, etc.)
-
Train employees on how to use and protect this data
-
Regularly audit and update the masking process to ensure it remains relevant
-
Monitor masked data for any suspicious activities, such as unauthorized access attempts and breaches
-
Perform masked data backups to make sure it’s recoverable
Concluding thoughts
Data masking will protect your data in non-production environments, enable you to share information with third-party contractors, and help you with compliance. You can purchase and deploy a data obfuscation solution yourself if you have an IT department and control your data flows. However, keep in mind that improper data masking implementation can lead to rather unpleasant consequences. Here are some of the most prominent ones:
-
Hindering productivity. The selected data masking techniques can cause large unnecessary delays in data processing, thereby slowing employees.
-
Becoming vulnerable to data breaches. If your data masking methods, or the lack thereof, fail to protect sensitive data, there will be financial and legal consequences up to serving time in prison.
-
Deriving inaccurate results from data analysis. This can happen if the data is masked incorrectly or too heavily. Researchers will misinterpret the experimental dataset and reach faulty conclusions that will lead to unfortunate business decisions.
Hence, if a company isn’t confident in its abilities to execute data obfuscation initiatives, it’s best to contact an external vendor who will help select the right data masking techniques and integrate the final product into your workflows with minimal interruptions.
Stay protected!








